Benchmarks that drive action: error drivers, not vibes
Accuracy percentages are useless without knowing what's failing and why. Here's how to build benchmarks that actually improve your system.
The accuracy trap
“Our extraction model is 94% accurate.”
This sounds good. But it tells you almost nothing useful:
- Which fields are failing?
- What document types cause errors?
- Are errors random or systematic?
- What should you fix first?
A single accuracy number is a vanity metric. It makes stakeholders feel good while hiding the information you need to improve.
What actionable benchmarks look like
Instead of one number, you need a breakdown that answers:
By field:
- Which specific fields have the highest error rates?
- Are some fields systematically underpredicted or overpredicted?
By document type:
- Do errors cluster in specific document formats?
- Are handwritten documents failing differently than typed ones?
By error type:
- Are values wrong, missing, or hallucinated?
- Are there systematic patterns (e.g., dates in European vs. US format)?
By confidence:
- Do low-confidence predictions correlate with errors?
- Is your confidence threshold calibrated correctly?
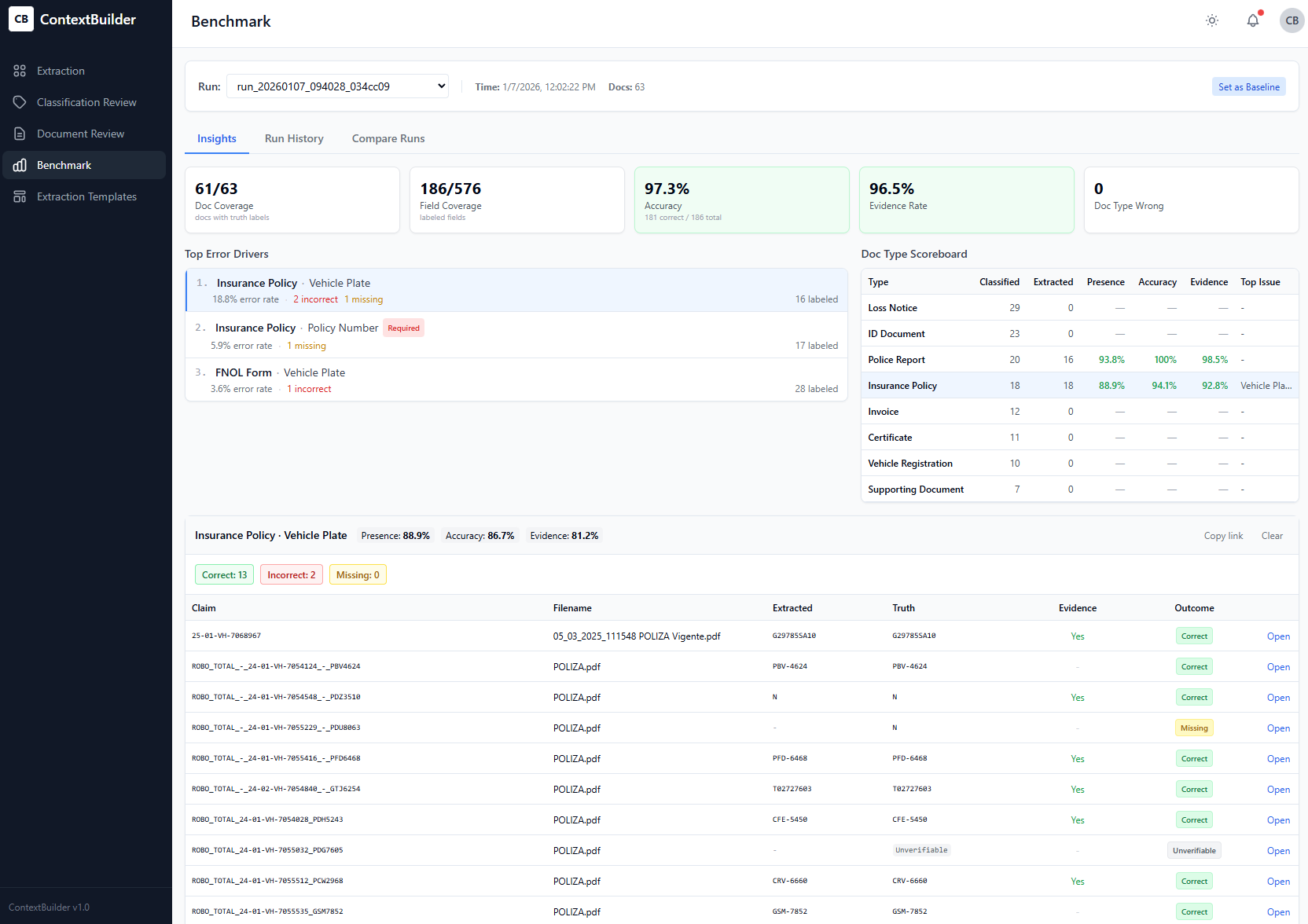
The error driver view
The most useful benchmark output is what I call the error driver view:
Top error drivers (last 30 days):
1. claim_date: 23% of errors — date format confusion (EU vs US)
2. policy_number: 18% of errors — OCR quality on scanned forms
3. claimant_name: 15% of errors — multi-party claims
4. amount: 12% of errors — currency symbol ambiguityNow you know exactly what to fix. Date format confusion? Add format normalization. OCR quality? Improve preprocessing. Multi-party claims? Adjust the extraction prompt.
Building the benchmark system
A good benchmark system has:
- Ground truth dataset — Manually verified extractions to compare against
- Automatic evaluation — Run on every model change, not just releases
- Drill-down reports — From aggregate metrics to specific failing examples
- Trend tracking — Is each error category improving or regressing?
The key is making it easy to go from “accuracy dropped” to “here are the 5 documents that started failing.”
The feedback loop
Benchmarks only matter if they drive action:
- Identify top error drivers
- Fix the root cause (prompt, preprocessing, or training data)
- Re-run benchmarks to verify improvement
- Repeat
This tight loop—measure, fix, verify—is how you turn a 94% model into a 98% model. Not by training bigger, but by fixing specific failure modes.
Beyond accuracy
The best benchmark systems also track:
- Latency — How long does extraction take per document?
- Cost — What’s the token/API cost per extraction?
- Coverage — What percentage of documents can you process automatically?
- Human review rate — How many extractions require manual verification?
These operational metrics matter as much as accuracy for production systems.
Want to see how I build evaluation into document intelligence systems? Check out the ClaimEval case study or get in touch.