
- Cut review time by routing only risky cases to humans
- Make outputs defensible with evidence links back to source pages
- Standardized QA checks across reviewers using the same rubric
- Industry
- Insurance
- Stack
- Python, LLM, n8n
Screenshots
Problem
Claims QA is slow, inconsistent, and hard to audit at scale—especially across lines like Motor and Home.
Constraints
No access to full SOP library at start; must work with partial guidance and be adaptable across lines of business.
The Approach
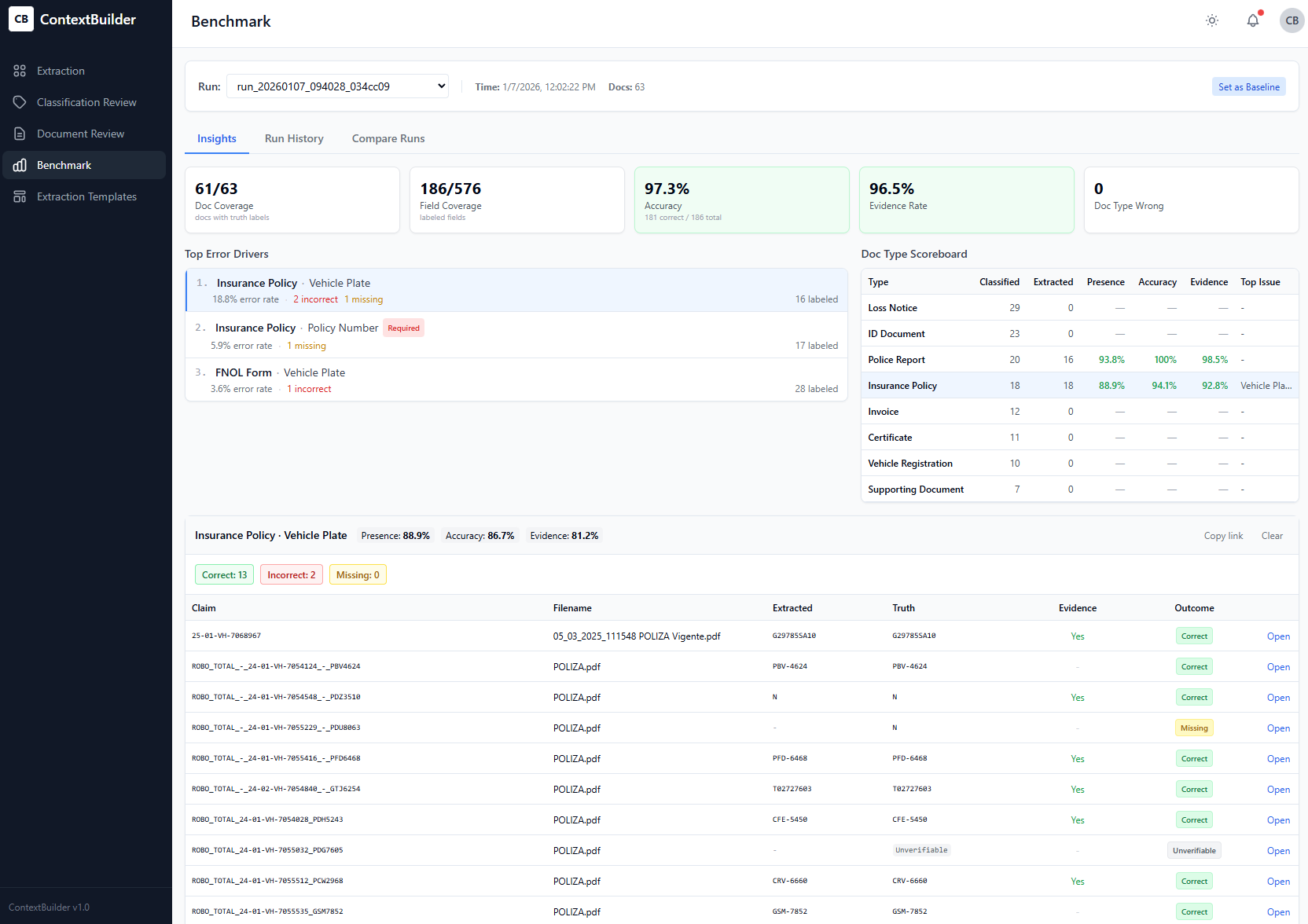
A structured QA workflow: ingest a claim file, extract key facts, run rule/checklist validations, produce a QA report with evidence and gaps.
Faster QA cycles, clearer audit trail, and a repeatable process that works across different claim types.
Context
ClaimEval is built for claims QA leaders, auditors, team managers, and adjusters who need feedback loops. It fits into post-settlement review, sampling audits, training feedback, and process compliance checks.
My role: Product + architecture + workflow design + prototype implementation.
The Problem
QA teams in insurance often face a nasty combination:
- High volume, limited capacity. Too many files, not enough reviewers.
- Inconsistent judgement. Different reviewers reach different conclusions on the same file.
- Weak evidence capture. “Why did we pass/fail this file?” is hard to answer.
- Training bottleneck. New reviewers can’t learn without a repeatable rubric.
When QA becomes a bottleneck, you either sample too little (risk) or drown your best people in manual review (burnout).
Key Decisions
-
Structure beats vibes. Every QA output is grounded in a checklist/rubric (per line of business, configurable) rather than free-form “LLM review.”
-
Evidence-first outputs. Every finding links to the supporting document excerpt or claim field. QA becomes defensible.
-
Gap detection as a first-class feature. Missing docs, inconsistent facts, and unanswered questions are surfaced explicitly—not buried in prose.
-
LOB adaptability. Motor and Home share workflow primitives (coverage, liability, documentation, settlement rationale) but differ in rubrics. Rubrics must be modular.
Solution Overview
ClaimEval produces a QA Report per file that includes:
- Claim summary: Key facts, dates, parties, loss description
- Checks performed: By category (documentation, coverage, liability, settlement, compliance)
- Findings: Pass / Fail / Needs Review
- Evidence links: Citations and snippets from the source documents
- Recommendations: What to correct, what to request, what to escalate
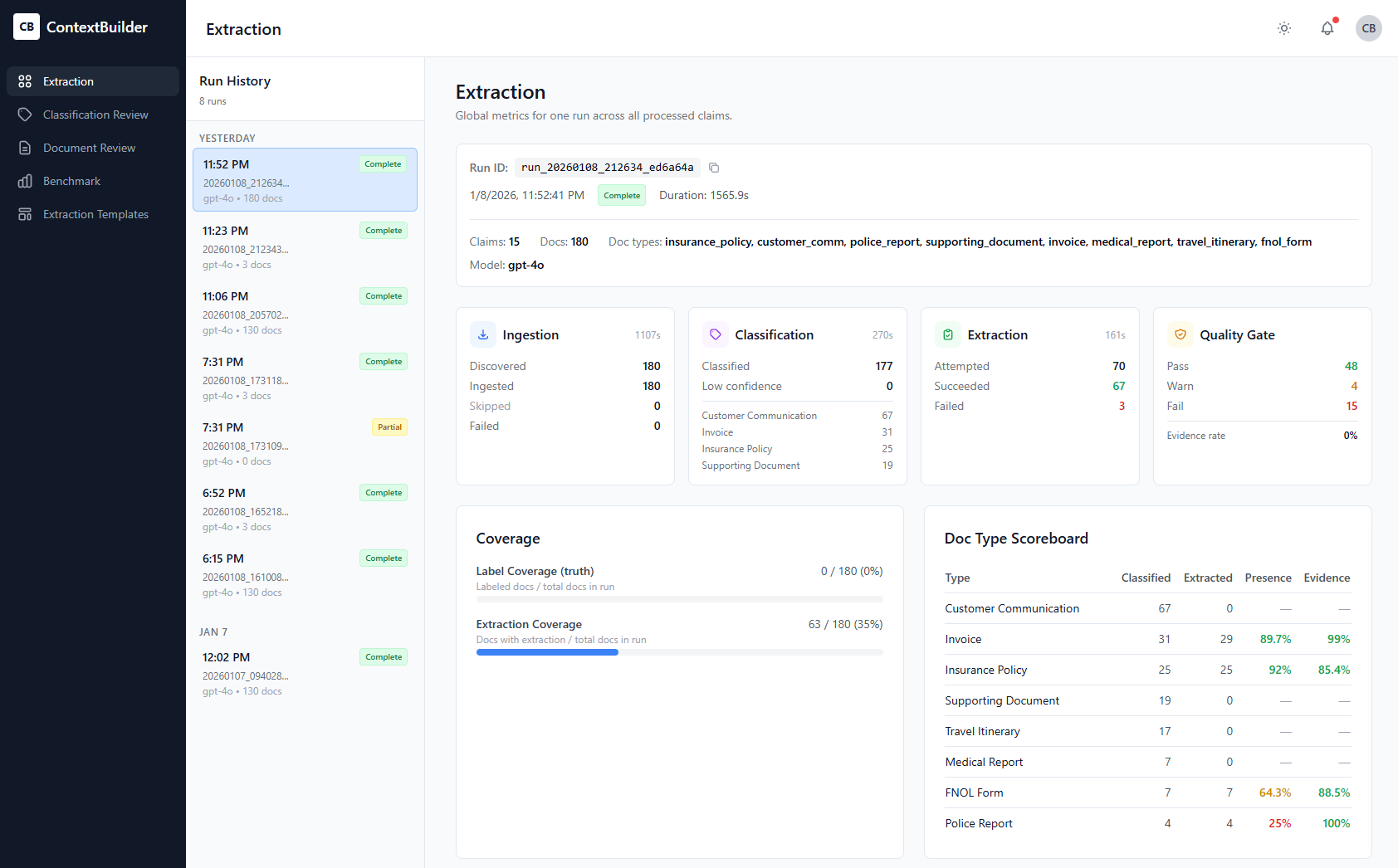
What I Built
- QA workflow skeleton: Ingest → Extract → Validate → Report
- Rubric-driven evaluation: Configurable checklists per line of business
- Report format: Consistent, scannable, audit-friendly
- Operator UX concept: Reviewers can approve, add notes, override with rationale
Outcome
- Efficiency: Reduced review time by structuring the evaluation process
- Consistency: Standardized checks across reviewers using the same rubric
- Auditability: Every decision has evidence + rationale attached
What I Learned
Building this taught me that the real challenge isn’t the AI—it’s the workflow design. A few insights:
- Rubric iteration is product work. QA leaders need to refine rubrics without engineering help. A small rubric editor would pay for itself.
- Calibration matters. Comparing reviewer decisions vs. copilot suggestions helps tune rubrics and build trust.
- Sampling intelligence is next. Prioritizing files that look risky (inconsistencies, missing docs, edge cases) would multiply the value.
- Trend analytics unlock training. Recurring issues by adjuster/team/claim type would turn QA from reactive to proactive.